Mudeli sobivuse kontroll
Olgu meil andmete põhjal hinnatud mudel, mille jaotusfunktsioon on 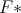 (mille
eeldame oleva pideva). Kas leitud mudel on ka andmetega kooskõlas? Nagu ikka on
esmaseks hindamise vahendiks graafilised meetodid. Kursuses eelnevealt mainitud
kvantiil-kvantiil graafik on üks võimalikke vahendeid. Selle graafiku joonistamiseks
kasutatava jaotusfunktsiooni pöördfunktsiooni rolli tuleb sel juhul võtta
(mille
eeldame oleva pideva). Kas leitud mudel on ka andmetega kooskõlas? Nagu ikka on
esmaseks hindamise vahendiks graafilised meetodid. Kursuses eelnevealt mainitud
kvantiil-kvantiil graafik on üks võimalikke vahendeid. Selle graafiku joonistamiseks
kasutatava jaotusfunktsiooni pöördfunktsiooni rolli tuleb sel juhul võtta 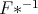 .
.
Olgu 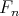 valimi põhjal leitud empiiriline jaotusfunktsioon. On selge, et funktsioon
valimi põhjal leitud empiiriline jaotusfunktsioon. On selge, et funktsioon
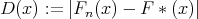 |
kajastab mudeli kooskõla andmetega. Seega on selle funktsiooni graafik samuti üks mudeli sobivuse hindamise vahendeid.
Mudeli sobivust on võimalik kvantifitseerida. Näiteks võime kaaluda nullhüpoteesi, et
andmed pärinevad mingist meile teadaolevast pidevast jaotusest 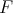 ning sisukaks
hüpoteesiks on sel juhul selle väite eitus – andmed ei pärine kirjeldatud jaotusest
ning sisukaks
hüpoteesiks on sel juhul selle väite eitus – andmed ei pärine kirjeldatud jaotusest 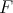 . Sellise
hüpoteesipaari kontrolliks on otstarbekas kasutada just nimelt funktsiooni
. Sellise
hüpoteesipaari kontrolliks on otstarbekas kasutada just nimelt funktsiooni 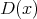 abi.
abi.
Kolmogorov-Smirnovi test baseerub teststatistikul
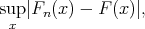 |
mille väärtust võrreldakse kriitilise väärtusega. Selle ületamisel kummutatakse
nullhüpotees. Ehkki pealtnäha keerukas on statistiku väärtuse leidmine tegelikult lihtne,
sest tänu 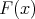 pidevusele ja empiirilise jaotusfunktsiooni “trepikujule” saavutab
funktsioon
pidevusele ja empiirilise jaotusfunktsiooni “trepikujule” saavutab
funktsioon 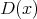 oma supreemumi ilmtingimata mõne valimi elemendi korral
või “vahetult enne seda”. Testi läbiviimist võimaldavad pea kõik statistikapaketid.
Reegel, mille vastu aga väga sageli eksima kiputakse on see, et
oma supreemumi ilmtingimata mõne valimi elemendi korral
või “vahetult enne seda”. Testi läbiviimist võimaldavad pea kõik statistikapaketid.
Reegel, mille vastu aga väga sageli eksima kiputakse on see, et  peab olema
valimist sõltumatult määratud. See tähendab, et me ei tohi võtta funktsiooni
peab olema
valimist sõltumatult määratud. See tähendab, et me ei tohi võtta funktsiooni  rolli funktsiooni
rolli funktsiooni  , sest selle parameetrid on eelnevalt valimi pealt hinnatud
ning siis ei pea Kolmogorov-Smirnovi test enam paika selles mõttes, et liiga sageli
jäädakse nullhüpoteesi juurde ehk testi võimsus langeb. Lahenduseks on siin
valimi juhuslik poolitamine – esimese poole põhjal hinnatakse jaotuse parameetrid
(s.o. leitakse
, sest selle parameetrid on eelnevalt valimi pealt hinnatud
ning siis ei pea Kolmogorov-Smirnovi test enam paika selles mõttes, et liiga sageli
jäädakse nullhüpoteesi juurde ehk testi võimsus langeb. Lahenduseks on siin
valimi juhuslik poolitamine – esimese poole põhjal hinnatakse jaotuse parameetrid
(s.o. leitakse  ) ning teise põhjal konstrueeritakse empiiriline jaotusfunktsioon
) ning teise põhjal konstrueeritakse empiiriline jaotusfunktsioon
 .
.
Illustreerime eelnevat ühe simuleerimiseksperimendiga. Esmalt genereerime  valimit
mahuga
valimit
mahuga  standardsest normaaljaotusest ja leiame iga kord Kolmogorov-Smirnovi
teststatistiku väärtuse kasutades ka
standardsest normaaljaotusest ja leiame iga kord Kolmogorov-Smirnovi
teststatistiku väärtuse kasutades ka  rollis standardset normaaljaotust. Teisel juhul
jätame genereerimise eeskirja samaks, ent kasutame
rollis standardset normaaljaotust. Teisel juhul
jätame genereerimise eeskirja samaks, ent kasutame  rollis normaaljaotust, mille
parameetrid on valimi põhjal hinnatud. Kolmandal juhul on valimid taas standardsest
normaaljaotusest aga jaotuse parameetrid hinnatakse vaid valimi esimese poole põhjal ja
jõutakse nii jaotuseni
rollis normaaljaotust, mille
parameetrid on valimi põhjal hinnatud. Kolmandal juhul on valimid taas standardsest
normaaljaotusest aga jaotuse parameetrid hinnatakse vaid valimi esimese poole põhjal ja
jõutakse nii jaotuseni  . Valimi teise poole abil aga konstrueeritakse
. Valimi teise poole abil aga konstrueeritakse 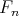 . Esimesel juhul
on leitud teststatistikute
. Esimesel juhul
on leitud teststatistikute 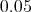 täiendkvantiil
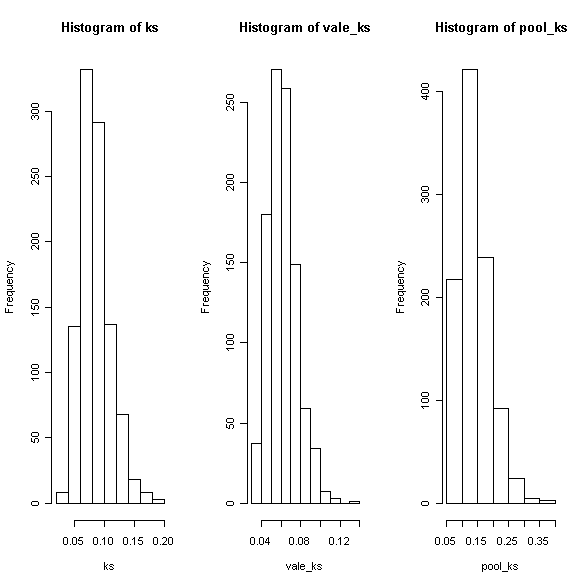
täiendkvantiil 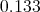 (see on kriitilise väärtuse hinnnang
sellise valimimahu korral, sest test on “jaotusvaba” põhinedes ainult jaotusfunktsiooni
väärtustel). Teisel juhul aga seda väärtust praktiliselt ei ületata ehkki tegelikult ei ole ju
ükski valim pärit hinnatud parameetritega jaotusest. Kolmandal graafikul on olukord juba
tunduvalt loogilisem – umbes pooltel juhtudel kriitiline väärtus ületatakse. Siin on küsimus
juba testi võimsuses.
(see on kriitilise väärtuse hinnnang
sellise valimimahu korral, sest test on “jaotusvaba” põhinedes ainult jaotusfunktsiooni
väärtustel). Teisel juhul aga seda väärtust praktiliselt ei ületata ehkki tegelikult ei ole ju
ükski valim pärit hinnatud parameetritega jaotusest. Kolmandal graafikul on olukord juba
tunduvalt loogilisem – umbes pooltel juhtudel kriitiline väärtus ületatakse. Siin on küsimus
juba testi võimsuses.
Anderson-Darlingi test asutab samuti funktsiooni 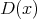 , ent jaotuse sabadele pannakse
siin lisarõhku. Teststatistikul on kuju
, ent jaotuse sabadele pannakse
siin lisarõhku. Teststatistikul on kuju
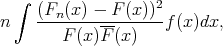 |
kus integraal on võetud üle kogu jaotuse kandja ja 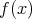 on jaotusele
on jaotusele 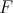 vastav
tihedusfunktsioon. Näeme, et see statistik põhineb sisuliselt funktsiooni
vastav
tihedusfunktsioon. Näeme, et see statistik põhineb sisuliselt funktsiooni 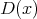 ruudu
keskmisel, ent see keskmine on kaalutud – suurte ja väikeste argumentide korral
võimendatakse väärtust tugevamalt. Teisalt on selline lähenemine igati mõistlik – kuivõrd
igasuguse jaotusfunktsiooni väärtus algab alati nullist ja lõpeb ühega siis on sabade
juures vastasel korral muidu garanteeritud väike jaotusfunktsioonide väärtuste
vahe. Ka selle testi korral peab paika, et
ruudu
keskmisel, ent see keskmine on kaalutud – suurte ja väikeste argumentide korral
võimendatakse väärtust tugevamalt. Teisalt on selline lähenemine igati mõistlik – kuivõrd
igasuguse jaotusfunktsiooni väärtus algab alati nullist ja lõpeb ühega siis on sabade
juures vastasel korral muidu garanteeritud väike jaotusfunktsioonide väärtuste
vahe. Ka selle testi korral peab paika, et 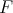 peaks olema andmetest sõltumatult
määratud.
peaks olema andmetest sõltumatult
määratud.